テキスト分析用アドオン「Text Coder X for SPSS」
テキスト分析用アドオン「Text Coder X for SPSS」

別のアプリを立ち上げる必要はなく、SPSSで開いた.savファイルに対して、以下をワンクリックで実行します。
- 日本語テキストの形態素解析(Sudachi)
- 品詞別のキーワード抽出
- 単語頻度データ・フラグデータの自動生成
専門知識がなくても、直感的にコーディングすることが可能です。
*ご利用にはSPSS Statistics バージョン29以上が必要です。
御見積依頼の方は
お問合せフォームより「Text Coder X for SPSS見積希望」の旨、ご連絡ください。
Text Coder X for SPSSの利用例
- 研究領域:質的インタビューのコーディングに
- 教育分野:授業フィードバック→改善施策との対応
- 顧客満足調査:評価の理由→購買継続率との関連
- 医療・看護:患者・看護記録→アウトカム指標との因果
- UX/サポート:問い合わせ履歴→障害・離脱原因の特定
- マーケティング:レビュー→ブランド要素の抽出
Text Coder X for SPSSの主な特徴
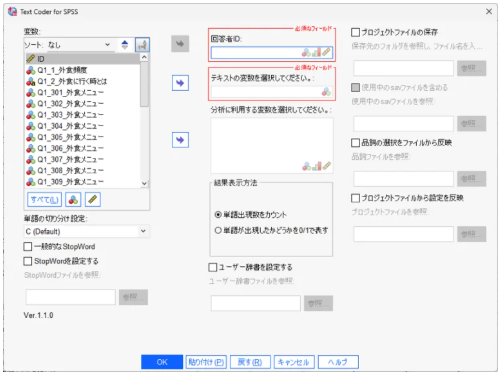
【1】SPSS Statisticsのメニューから操作が可能
別ツールを起動することなく、テキストデータから品詞を抽出し、テキストデータを利用することができます。
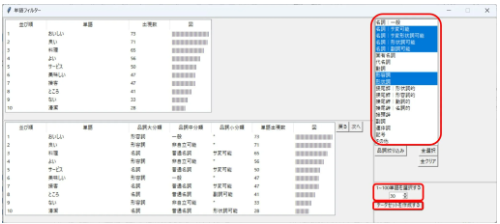
【2】テキストデータを指定してキーワードを抽出
文章から名詞・動詞・形容詞などを抽出し、出現頻度順で一覧表示。
分析したい品詞だけにフィルタリング可能。初心者でも“次に何を見るか”が明確になります。
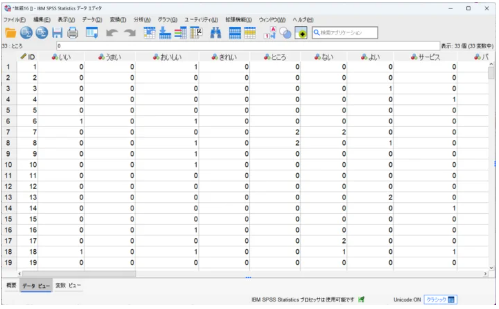
【3】コード化された .sav ファイルを即生成
分析者が最も使いやすい2つの形式を自動出力
- 単語頻度ファイル:回答者ごとの出現回数
- フラグファイル:単語使用有無(0/1)
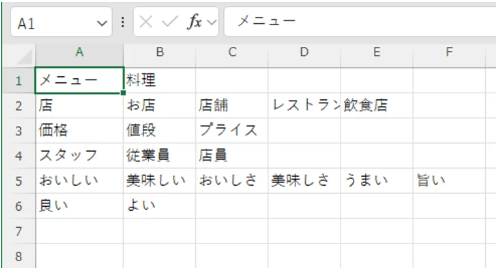
【4】辞書機能(同義語統合・ストップワード)
独自辞書を登録し、語のゆれや同義語を統合。
不要語(助詞・一般語)もストップワードで除外可能。
- 「クレーム」「苦情」「要望」→“不満”カテゴリに統合
- 「です」「こと」「今回」→除去
自社・研究領域に適合したコーディング体系を構築できます。
【5】プロジェクトファイルで分析資産を管理
辞書・品詞設定・対象データをzip形式で一括保存。
研究室・部門間・共同研究で再現性の高い分析プロトコルを共有できます。
コード化されたデータをさらに分析
- 関連マップによる共起関係の可視化
- 階層クラスタで類似単語を分類
- コレスポンデンス分析(要Categoriesオプション)
Text Coder X for SPSSの稼働環境
- IBM SPSS Statistics v29以上(Base/Standard 推奨)
- OSはSPSSの対応環境に準拠
– Windows 10 / 11
– MacOS 最新版(SPSSサポート範囲)
価格
Text Coder X for SPSS (1年間無償アップグレード付)
ご購入から1年以内に新バージョンがリリースされた場合には無償でアップグレードが可能
標準価格 ¥50,000.-(税別)
キャンペーン価格(~2026/03/31)¥40,000.-(税別)
Text Coder X for SPSS アップグレード (1年間無償アップグレード付)
無償期間を過ぎてアップグレードをご希望のお客様向けに、アップグレードライセンスをご用意しております。
標準価格 ¥30,000.-(税別)
納品方法
- Eメールにて、ダウンロードリンクおよびインストール方法のご案内をお送りいたします。
- Text Coder X for SPSSは、認証コード等はなく、プログラムをSPSSへインストールするのみでご利用いただけます。
- インストール用メディア(DVDなど)のご提供はしておりません。
備考
License販売元は問いません。
Text Coder X for SPSSについての御見積をご希望の方は
「Text Coder X for SPSS見積希望」の旨、ご連絡ください。
連絡先
IBM SPSS Statistics製品をお持ちでない方は、御見積依頼フォームよりご連絡ください。
SPSS専用見積依頼フォーム
※備考欄に「IBM SPSS Statistics製品の見積もりの他にText Coder X for SPSSの見積もりも希望」とご記載ください



